First of all this is not an "expert review" and it will be totally bias. Not that I am a fan boy of one brand or another, but I really dedicate myself to find what I want.
REVIEW
For this round I needed to find a laptop that fits all my needs like:
- Power for development (lots of RAM, decent CPU, lots of memory)
- Small and light so it can be with me almost everywhere (work, home, on the go...)
- Touch screen and Windows 8 (to have latest technology changes)
In my wish list of laptops before I found the
VAIO SVE14A390X the contenders were:
MacBook Pro - Retina Display and
Asus Zenbook - UX51VZ. But after considering issues I felt with those machines, not having touch screen for Windows 8, and the excessive price (at the moment $2500+), I finally hit the spot with the VAIO SVE14A. The
VAIO SVE14A390X Premium Plus is a customized version direct from Sony Store. For flat $2000 I got a machine with very similar specs to the ones I was looking for and more...
These are some of the highlights:
- 3rd gen Intel® Core™ i7-3632QM quad-core processor (2.20GHz / 3.20GHz with Turbo Boost)
- 16GB RAM DDR3 @1600MHz
- AMD Radeo HD 7670M (2GB) hybrid graphics
- 1TB Hard disk @ 5400 RPM
- Touch screen
- Windows 8 Pro
- 2 year SONY Protection plan (covers fall, spills, etc..)
- Customization / additions included in the $2000 budget
My benchmark for performance was the
Asus Zenbook - UX51VZ. After switching the hard disk for SSD, I got to say the results are very close. Also not having a RAID 0 SSD configuration is mind easing. SSD are dangerous still for reliability so adding RAID 0 to the mix is not really something I am looking for. Plus many reports questions RAID 0 over SSD, but this is just derailing the focus. Graphics performance are satisfactory but I don't play games so I am good. The noise of the fan is ok when hot but otherwise is silent. Surprisingly the temperature of the machine never gets hot bottom or top wise, and this was after installing software for hours.
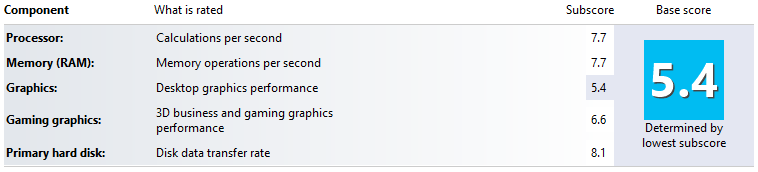
So comparing Windows Experience Index we can see the following results:
UX51VZ
SVE14A390X Premium Plus
Look at the hard disk transfer rate increasing from 5.9 to 8.1. Also the memory operation per second went down, but I am guessing this part of not being good benchmark test process. Just simple execute and done tests.
OEM Hardware
With Custom SSD
ENHANCEMENTS
Swap HDD for SSD
The only major customization is swapping the HDD (hard disk) for the SSD (solid state drive). Before I did it myself, I google around for DIY / tutorials about what is needed. Unfortunately the information I found can be quite confusing for such an easy process. For this scenario we are keeping the original configuration from the recovery disk and do a new install in the SSD. Please don't just install an image in the SSD as this can result in bad performance and premature damage to your SSD.
1. Create the Recovery Media
Sony doesn't distribute the Recovery Disks anymore. Instead they exists in a partition of your OEM disk. All you have to do is
follow the instructions in this link to burn the recovery disks.
2. Swap the HDD for SSD
Below are some images of the swap, but this should be plug and play. Just take your time and don't force anything. The only important note is to swap the bracket holding the HDD in place and place it in the SSD as shown in the photos below.
3. Re-install the system with Recovery Media
Once you finish placing the SSD now you need to install Windows 8 OS.
Follow this link for the instructions. I got to say I am surprise with how easy is with Windows 8 to re-install the OS. No questions about disk partition, file system format, etc... Even no need to specify the activation as with Windows 8 this is kind of built in into the hardware (
I think motherboard).
Replace DVD for HDD
Now for the other modification of converting the DVD player into a secondary HDD. For that we need the
caddy to hold the HDD. The process is simple but
take your time! There are plenty of tiny screws and the face plate is fragile. Read the following
instructions prior to starting the swap.
The only "hard" steps is shown below in the photos. The trick for taking the face plate out press the tab down while pulling the plate in a rotational motion. I don't remember the exact direction of the rotation, but just
don't pull straight. This is plastic so if you break it, you are going to be sorry.
The results. Well the machine is a little heavier but not enough to make a real difference because this is not an ultrabook light. Actually, having the hard drive makes the machine more sturdy when I grab it on that side versus feeling hollow. Meaning I can hold it with a solid grip without worrying. Having a 1TB disk is awesome for system image backups, store movies, ISOs, etc. Since this is the OEM disk, it contains partitions for recovery and even Windows 8 still installed for the case my SSD fails and I need to react quick. Noise and heat is the same or none.
Only weird finding is that I can access my old user account in Windows 8 partition. I don't know what credential Windows 8 in the SSD found to give me access to the old user account, but that sounds like security breach to me.
Press the tab:
While pulling in a rotational manner because the tabs have hooks: